
Abstract
- External website resources can de references toward existing, expired or incorrect domain names.
- We have requested a total of 88000 sites including 54000 from Alexa top 1M as well as 34000 from Majestic top 1M to search each homepages for broken external resources.
- 35.2% of home pages have one or more broken links.
- These high traffic sites can be perfect candidates for a Broken Link Hijacking attack
- In the next step of our study, we will register expired domain names extracted from broken links to analyze incoming traffic.
1. The Danger of Expired Developers Websites
What would happen if the www[.]google-analytics[.]com domain present on billions of sites expired and was not renewed? The unmaintained sites could then serve up outdated code that would attempt to load and run scripts in vain. A third party could take over the expired domain and distribute malicious code under it. This is known in offensive security as Broken Link Hijacking.
In the best case, a broken link will simply result in a bad user experience. In the worst case, it will pose a threat to the cybersecurity of anyone visiting the website.
Depending on how the link is used in the website code, there are several ways to exploit the vulnerability, with varying risk levels.
2. Dead Links, a Thirty Years Old Issue
The problem of broken links (or dead links) is a web phenomenon observed since the 1990s. At that time, 3% of all hyperlinks became broken after one year (Nelson and Allen, 2002). On average, all URL links combined, the average lifespan is two years (Hans van der Graaf, 2017).
The problem has been covered mainly in the field of academic research. Indeed, a scientific publication that cites its sources through hypertext links could pose problems of credibility, peer review and reproducibility of results.
On the other hand, the status of hyperlinks (error code of external resources called by a website to render a service to the user) are less or not studied. This can concern the storage of an image, a video, a JavaScript code or a style sheet (CSS) for example. Depending on the nature of the unavailability of the resource, questions of computer security arise, in particular through the weaponization of these anomalies for malicious purposes.
2.1 Broken Ressources Links
Hypertext links are by definition the very basis of the web. They link web resources together and allow visitors to navigate between pages, to have dynamic content and ergonomic rendering.
Here is an example of links that can exist on a properly configured site:
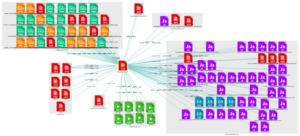
This is what it looks like on a site with a large number of broken links:
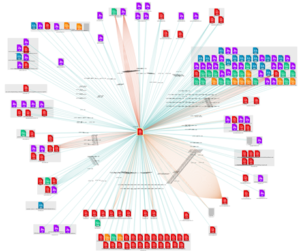
However, although valid at the time of the creation of the web site, these resources evolve over time and may disappear: libraries are no longer maintained, domains are not renewed subdomains forgotten or stolen, servers are closed. The web is dynamic and resources that are available today may not be available tomorrow.
But some broken links can be broken as soon as a website is online, because of programming errors or typos in the addresses used.
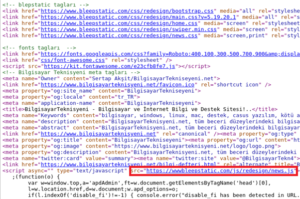
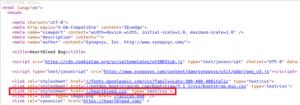
Below is a broken link due to an error by the programmer who forgot a point for loading this script which is therefore loaded on “wwwbleepstatic[.]com” instead of “www[.]bleepstatic[.]com”.
In the site below a slash has been forgotten between the domain in “.fr” and the resource to be loaded, so the browser tries to resolve a domain with a “.frundefined” extension.
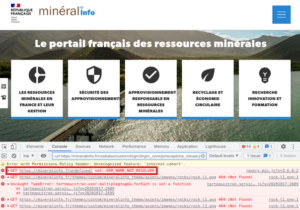
2.2 Broken Link Hijacking
In the best case, a broken link will simply result in a bad user experience or even be small changes in the page. But in the worst case, it will pose a threat to the cybersecurity of anyone visiting the website.
Typical link hijacking attacks are the following:
- Library Hijacking: Links to libraries removed and replaced by another namesake.
- Domain Hijacking: Links to expired domains that can be registered or purchased.
- Subdomain Hijacking: Links to subdomains that are no longer in use and are vulnerable to takeover.
Here is an example of a broken link in a page footer resulting in an impossible loading of an image by the browser, the latter signals it by displaying a broken image:
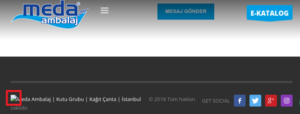
Even in the field of security some sites are affected, like the infamous OpenSSL hearthbleed which tries to load a CSS style flaw on “heartbleed.css” which of course is not a valid domain.
If a malicious actor successfully hijack a called external resources, he could inject scripts executed by the victim’s browser and harm the sites reputation and the visitor of the webpage. A broken image or CSS link could be used to deface a website. More seriously, a broken link allowing to execute code would open the door to data theft, server takeover or hacking of its visitors.
2.3 Unmaintained high traffic websites
A particular case of broken links is the non renewal of a domain name by its owner. Like a lease, each domain name is assigned to its owner for a given period of time. In case of non-payment or non-renewal of the lease, the domain name is again available for purchase. This non-renewal can be an oversight, or a pure and simple abandonment following a merger-acquisition for example.
One of the first famous cases was the non-renewal of the domain owned by Microsoft, passport[.]com, at the end of 1999. This domain was used for authentication on the Hotmail mailbox. The domain name was renewed by a vigilant user, who was reimbursed soon after by Microsoft. The same story is repeated in October 2003 with the domain hotmail[.]co[.]uk.
Other organizations, from the most modest to the giants of the Tech like FourSquare in 2010 or Google Argentina in April 2021 have failed to manage their domain name renewal properly, fortunately without any harmful effect.
In 2020, researchers at Palo Alto security firm Unit42 found that previously expired “parked” domains (purchased to simply be put up for sale) were being used to spread the Emotet malware. According to their analysis, 1% of parked domains were being used for malicious purposes, a potential 3,000 domains per day.
In 2021, researchers at security firm Sucuri uncovered an attack exploiting the unrenewed domain tidioelements[.]com of the defunct WordPress plugin “visual-website-editor”. Hackers registered this domain name to inject malicious javascript code into it.
The malicious reuse of abandoned domains can also be a very effective vector for phishing or fraud, using the brand and reputation of the organization that originally owned the domain name.
3. Research Methodology
Our main hypothesis is that very high traffic sites may have broken links. We also believe that some of these links are broken due to domain name expiration and therefore subject to link hijacking attacks.
For investigative purposes, we have developed a crawler to scan sites in the same way as a user visiting the site with his browser.
This robot is specific to a surface scan: it comes to browse a list of domains from Alexa’s lists, inspects the external references called by the HTML code of the visited homepages and retrieves the information about broken links.
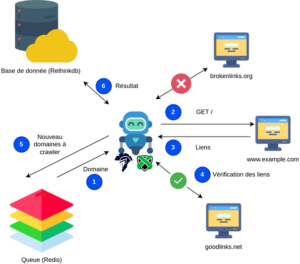
The way the robot analyzes HTML pages is as follows: for each home page visited, the robot records all the dependencies, their type (script, img, css, …), their size as well as the HTTP response codes (200, 302, 404, …).
If the domain of the resource does not exist and is a valid domain name, then the robot retrieves the whois records if it exists.
The code of the robot had to be adapted several times following the discovery of new cases of blocking such as limitations on the number of whois requests, sites that load dependencies continuously, sites that take too long to respond.
4. Experimentation Results
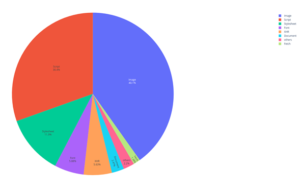
We analyzed 88,000 home pages extracted from Majestic and Alexa. We identified a total of 6,325,915 links to external resources, of which 1,052,244 are broken (16.63%).

Images and JavaScript codes represent a little more than 70% of the external resources.
| Typical resource | Number | % |
| Image | 2536692 | 40,263% |
| Script | 1923078 | 30,213% |
| Stylesheet | 752783 | 12,312% |
| Font | 371963 | 5,825% |
| XHR | 354251 | 5,708% |
| Document | 163208 | 2,458% |
| Fetch | 120825 | 1,191% |
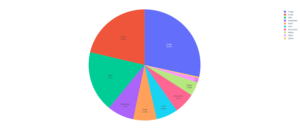
Of the 88,000 home pages, 30960 have at least one broken link (35.2%).
Images as well as XMLHttpRequest objects, and JavaScript codes represent a little over 70% of the invalid external resources.
| Typical resource | Number | % |
| XHR | 323039 | 30,672% |
| Image | 292524 | 27,777% |
| Script | 170464 | 16,173% |
| Stylesheet | 68396 | 6,513% |
| Fetch | 54717 | 5,156% |
| Font | 53002 | 5,037% |
| Document | 48003 | 4,562% |
| Media | 30747 | 2,922% |
| Other | 9933 | 0,944% |
| Preflight | 1905 | 0,181% |
| Ping | 663 | 0,063% |
| EventSource | 1 | 9.5e(-5)% |
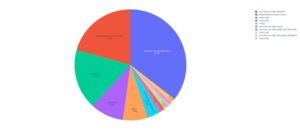
The most frequent causes of errors are mixed-content, resources not found (HTTP 404 and javascript net::ERR_ABORTED) and resources under access restrictions (HTTP 403) represent almost 70% of errors:
| Error Type | Number of hits | % |
| blockedReason|mixed-content | 359752 | 34,189% |
| errorText|net::ERR_ABORTED | 169979 | 16,154% |
| status|404 | 99311 | 9,438% |
| status|403 | 98848 | 9,394% |
| errorText|net::ERR_FAILED | 29000 | 2,756% |
| errorText|net::ERR_NAME_NOT_RESOLVED | 14279 | 1,357% |
| errorText|net::ERR_INSUFFICIENT_RESOURCES | 11796 | 1,121% |
| errorText|net::ERR_TOO_MANY_REDIRECTS | 11217 | 1,066% |
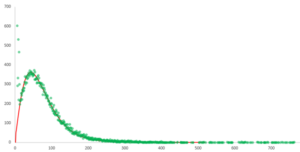
On average, we have determined that the home page of a site has 72 dependencies. 60% are internal and 40% external.
The distribution thus mainly observed is a gamma distribution. This point is interesting and allows us to partially model the distribution of the number of dependencies per site. We also notice that the beginning of the distribution does not correspond to a gamma distribution: our hypothesis is that this distribution is the sum of at least two different distributions. Because of the small number of points, it is not possible to determine it. We can simply see that it is strictly monotonic and decreasing.
Top 10 most referenced links
- https://facebook.com
- https://twitter.com
- https://instagram.com
- https://youtube.com
- https://linkedin.com
- https://google.com
- https://pinterest.com
- https://wordpress.org
- https://apple.com
- https://vk.com
5. Results Interpretation
Looking at our analysis, we can see that 35.2% of home pages have at least one broken link that can be takeover by a malicious person, regardless of the type of error. If this percentage seems low, it must be brought back to the order of magnitude of the web. According to the World Economic Forum, in 2021, there was 1.88 billion websites. Thus, about 662 million websites could be affected and present a risk.
By taking some samples, for a qualitative approach, we noticed that programming errors are often at the origin of these broken links : badly placed dots, inverted letters, forgotten “/” separators between the domain and the resource, or even the resource taken for the domain (example: loading https://ressource[.]js instead of https://<domain>/resource.js (sic)). This means that these anomalies are present before the production release and it reflects a lack of implementation of the test phases.
Another category of anomaly that is very present concerns domain names not renewed by advertising agencies or web design agencies. This could be explained by a bad follow-up of the expiration dates of the domains or by the cessation of the company’s activities.
If some sites require only a few resources, others can have several hundred. In particular, advertising agencies play a major role in this number of requests.
The average resource value per web page is an interesting metric to observe, as each resource is an additional risk vector for the site. Some of these external resources can be critical for the proper functioning of the site. If some anomalies can be very visible quickly, others affecting background resources are more difficult to detect.
6. Experiment Limitations
The non-exhaustiveness of our lists of domains necessarily implies the introduction of a sampling bias. Indeed, the analyzed sites necessarily belong to a domain of interest to the general public (e.g. e-commerce, blog, etc.), but it is the conscious choice of this study to focus on the maximum possible impact in case of malicious use. On the other hand, these sites with very high traffic may rely more than others on CMS. Thus, our analysis could not be that of high traffic sites, but that of the underlying technologies and methodologies used to develop them.
It is also important to take into account the temporal aspect of the web and its volatility: what is true today may not be true tomorrow. If we were to do the same experiment in the future with the same infrastructure and the same protocol, we might find different statistical results.
7. Research Opportunities
To go further in our exploration of the web we could scan these same high traffic sites in depth (e.g. Majestic Million) to analyze the percentage of broken links on the entire site, and not just its home page.
We could also repeat the test every six months or every year, in order to analyze trends on external references and their associated anomalies.
In the immediate future, our next research focuses on a particular case: the purchasable expired domains present in the broken links. Being available for purchase, it is thus possible to recover them and analyze all the traffic inherited from the old service. It should thus be possible to make statistics on this traffic (bot, user agent, OS, etc.) in a completely passive way.
8. Conclusion
In conclusion we could see that broken links are omnipresent on the web and especially concerning external resources. If researches exist on the phenomenon of dead links in texts and web site architecture, as well as on the use of vulnerable external libraries, we did not find any academic references on our particular subject of dead links in external resources references.
Our preliminary research indicates that potentially hundreds of millions of sites are affected by this problem on their landing page. They may present a risk to the visitor of being distributed malicious content and a risk to the company hosting the site of damage to its image.
We will continue our research, purchasing expired domain names and analyzing traffic to better understand which populations might be targeted in the event of a malicious operationalization of this endemic web anomaly.
9. About the authors
Nicolas and Laurent are both passionate about DIY and cybersecurity, having decided to create their own digital security company: X-Rator and Spartan conseil, respectively.
Having each complementary skills, they decided to join hands and write a series of articles on cybersecurity, to the delight of readers.

